Persona-1

Expressive talking heads, running faster than realtime.

Persona-1 is an expressive, faster than realtime talking head model. In building Persona-1, we made a few tradeoffs to favor speed over generalizability, uniquely enabling realtime interactions with personas at scale.
Architecture Overview
Persona-1 is a flow-based image transformer, trained in two stages:
- In Stage 1, we learn highly compressed image representations
- In Stage 2, we learn a mapping from audio to the compressed image representations
The first stage establishes a person specific auto-encoder by training an encoder-decoder with a flow matching objective, as seen in the diagram below.
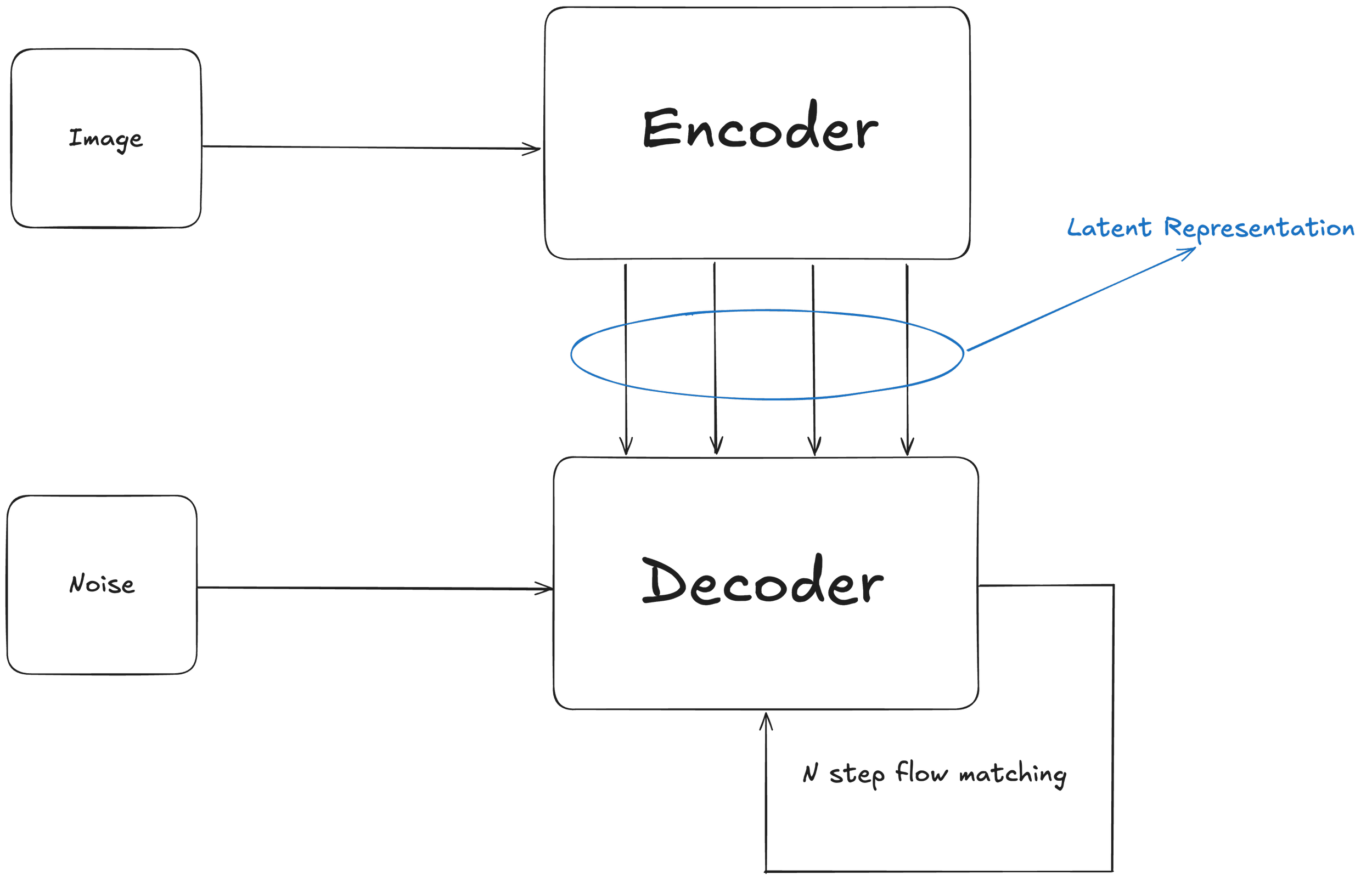
The auto-encoder formulation for Stage 1 has two main benefits:
- Extremely high rates of compression — we effectively compress input images by 1024x
- An emergent “pseudo-linear” latent space, significantly reducing the complexity required of Stage 2
The second stage is then a rather straightforward encoder-decoder transformer that maps audio embeddings to the latent representations learned by Stage 1.
Performance
The setup allows us to auto-regressively generate images at extremely high throughput.
| GPU | Real-Time Factor (RTF) |
| -------- | ---------------------- |
| RTX 4090 | 0.5 |
| L40s | 0.25 |
| H100 | 0.0625 |
On last-gen consumer hardware (RTX 4090), Persona-1 runs at ~2x real time (RTF ≈ 0.5). On low-cost enterprise hardware (L40S), it achieves ~4x real time (RTF ≈ 0.25), serving up to eight live streams in parallel.
Notably, these results come with minimal loss in expressivity relative to the dataset — we invite you to try it yourself in our playground.
Limitations & Future Work
Generalizability. As a person-specific model, Persona-1 requires a non-trivial amount of input data (~30–45 minutes) to adapt to a new identity — a feasible requirement for many of its initial use cases. Follow-up experiments indicate Persona-1 is able to learn a base representation across multiple subjects, and quickly adapt to new subjects with <5 minutes of data.
Resolution. Persona-1’s architecture scales effectively to higher resolutions, allowing a trade-off between latency and quality. Ongoing research in optimizing the model’s architecture shows promise.
Pricing & Availability
Persona-1 is currently in early access, with costs as low as a few cents per minute, ~1/2 the cost of the cheapest competing models.
| Model | Price per minute (USD) |
| ----------- | ---------------------- |
| Persona-1 | $0.025 |
| Competitors | $0.050 |
We’re excited to see what sorts of novel applications Persona-1 enables.

